publications
2024
-
 Arraybot: Reinforcement Learning for Generalizable Distributed Manipulation through TouchZhengrong Xue*, Han Zhang*, Jingwen Cheng, Zhengmao He, Yuanchen Ju, Changyi Lin, Gu Zhang, and Huazhe XuIEEE International Conference on Robotics and Automation (ICRA) 2024
Arraybot: Reinforcement Learning for Generalizable Distributed Manipulation through TouchZhengrong Xue*, Han Zhang*, Jingwen Cheng, Zhengmao He, Yuanchen Ju, Changyi Lin, Gu Zhang, and Huazhe XuIEEE International Conference on Robotics and Automation (ICRA) 2024We present ArrayBot, a distributed manipulation system consisting of a 16x16 array of vertically sliding pillars integrated with tactile sensors, which can simultaneously support, perceive, and manipulate the tabletop objects. Towards generalizable distributed manipulation, we leverage reinforcement learning (RL) algorithms for the automatic discovery of control policies. In the face of the massively redundant actions, we propose to reshape the action space by considering the spatially local action patch and the low-frequency actions in the frequency domain. With this reshaped action space, we train RL agents that can relocate diverse objects through tactile observations only. Surprisingly, we find that the discovered policy can not only generalize to unseen object shapes in the simulator but also transfer to the physical robot without any domain randomization. Leveraging the deployed policy, we present abundant real-world manipulation tasks, illustrating the vast potential of RL on ArrayBot for distributed manipulation.
-
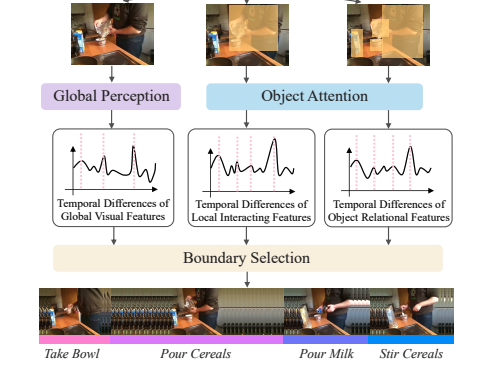 OTAS: Unsupervised Boundary Detection for Object-Centric Temporal Action SegmentationYuerong Li, Zhengrong Xue, and Huazhe XuIEEE/CVF Winter Conference on Applications of Computer Vision (WACV) 2024
OTAS: Unsupervised Boundary Detection for Object-Centric Temporal Action SegmentationYuerong Li, Zhengrong Xue, and Huazhe XuIEEE/CVF Winter Conference on Applications of Computer Vision (WACV) 2024Temporal action segmentation is typically achieved by discovering the dramatic variances in global visual descriptors. In this paper, we explore the merits of local features by proposing the unsupervised framework of Object-centric Temporal Action Segmentation (OTAS). Broadly speaking, OTAS consists of self-supervised global and local feature extraction modules as well as a boundary selection module that fuses the features and detects salient boundaries for action segmentation. As a second contribution, we discuss the pros and cons of existing frame-level and boundary-level evaluation metrics. Through extensive experiments, we find OTAS is superior to the previous state-of-the-art method by 41% on average in terms of our recommended F1 score. Surprisingly, OTAS even outperforms the ground-truth human annotations in the user study. Moreover, OTAS is efficient enough to allow real-time inference.
2023
-
 USEEK: Unsupervised SE(3)-Equivariant 3D Keypoints for Generalizable ManipulationZhengrong Xue, Zhecheng Yuan, Jiashun Wang, Xueqian Wang, Yang Gao, and Huazhe XuIEEE International Conference on Robotics and Automation (ICRA) 2023
USEEK: Unsupervised SE(3)-Equivariant 3D Keypoints for Generalizable ManipulationZhengrong Xue, Zhecheng Yuan, Jiashun Wang, Xueqian Wang, Yang Gao, and Huazhe XuIEEE International Conference on Robotics and Automation (ICRA) 2023Can a robot manipulate intra-category unseen objects in arbitrary poses with the help of a mere demonstration of grasping pose on a single object instance? In this paper, we try to address this intriguing challenge by using USEEK, an unsupervised SE(3)-equivariant keypoints method that enjoys alignment across instances in a category, to perform generalizable manipulation. USEEK follows a teacher-student structure to decouple the unsupervised keypoint discovery and SE(3)-equivariant keypoint detection. With USEEK in hand, the robot can infer the category-level task-relevant object frames in an efficient and explainable manner, enabling manipulation of any intra-category objects from and to any poses. Through extensive experiments, we demonstrate that the keypoints produced by USEEK possess rich semantics, thus successfully transferring the functional knowledge from the demonstration object to the novel ones. Compared with other object representations for manipulation, USEEK is more adaptive in the face of large intra-category shape variance, more robust with limited demonstrations, and more efficient at inference time.
2022
-
 Pre-Trained Image Encoder for Generalizable Visual Reinforcement LearningZhecheng Yuan, Zhengrong Xue, Bo Yuan, Xueqian Wang, Yi Wu, Yang Gao, and Huazhe XuConference on Neural Information Processing Systems (NeurIPS) 2022
Pre-Trained Image Encoder for Generalizable Visual Reinforcement LearningZhecheng Yuan, Zhengrong Xue, Bo Yuan, Xueqian Wang, Yi Wu, Yang Gao, and Huazhe XuConference on Neural Information Processing Systems (NeurIPS) 2022Learning generalizable policies that can adapt to unseen environments remains challenging in visual Reinforcement Learning (RL). Existing approaches try to acquire a robust representation via diversifying the appearances of in-domain observations for better generalization. Limited by the specific observations of the environment, these methods ignore the possibility of exploring diverse real-world image datasets. In this paper, we investigate how a visual RL agent would benefit from the off-the-shelf visual representations. Surprisingly, we find that the early layers in an ImageNet pre-trained ResNet model could provide rather generalizable representations for visual RL. Hence, we propose Pre-trained Image Encoder for Generalizable visual reinforcement learning (PIE-G), a simple yet effective framework that can generalize to the unseen visual scenarios in a zero-shot manner. Extensive experiments are conducted on DMControl Generalization Benchmark, DMControl Manipulation Tasks, and Drawer World to verify the effectiveness of PIE-G. Empirical evidence suggests PIE-G can significantly outperforms previous state-of-the-art methods in terms of generalization performance. In particular, PIE-G boasts a 55% generalization performance gain on average in the challenging video background setting.
2021
-
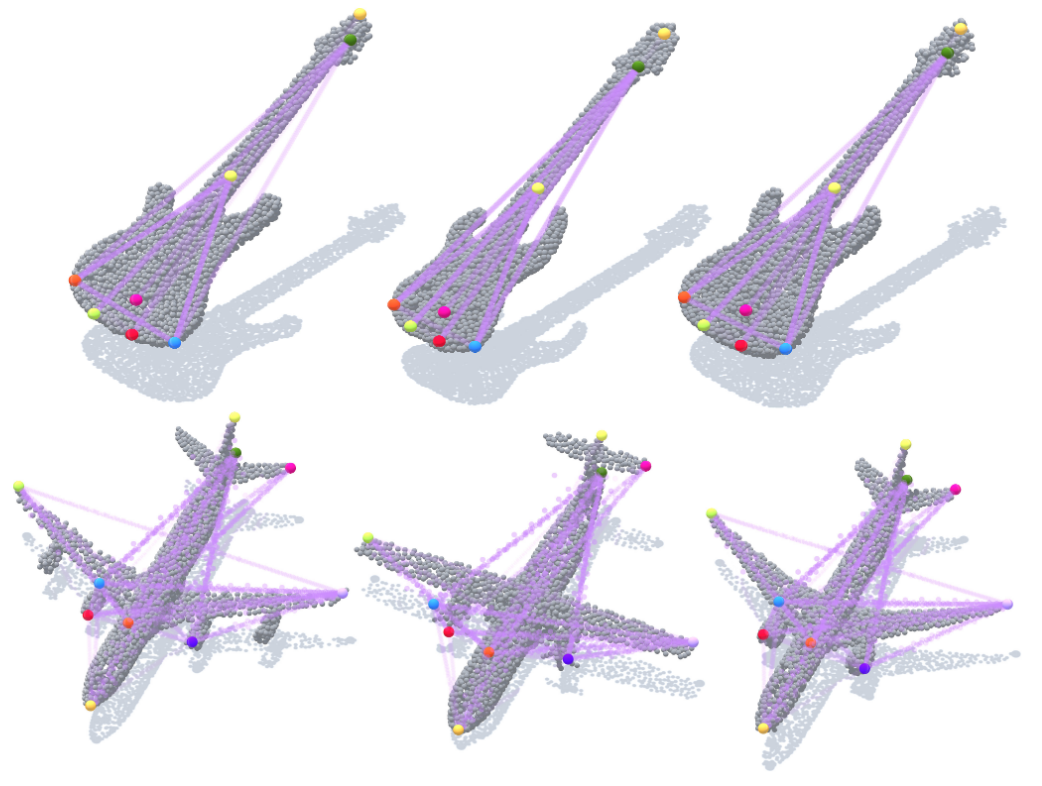 Skeleton Merger: an Unsupervised Aligned Keypoint DetectorRuoxi Shi, Zhengrong Xue, Yang You, and Cewu LuIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2021
Skeleton Merger: an Unsupervised Aligned Keypoint DetectorRuoxi Shi, Zhengrong Xue, Yang You, and Cewu LuIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2021Detecting aligned 3D keypoints is essential under many scenarios such as object tracking, shape retrieval and robotics. However, it is generally hard to prepare a high-quality dataset for all types of objects due to the ambiguity of keypoint itself. Meanwhile, current unsupervised detectors are unable to generate aligned keypoints with good coverage. In this paper, we propose an unsupervised aligned keypoint detector, Skeleton Merger, which utilizes skeletons to reconstruct objects. It is based on an Autoencoder architecture. The encoder proposes keypoints and predicts activation strengths of edges between keypoints. The decoder performs uniform sampling on the skeleton and refines it into small point clouds with pointwise offsets. Then the activation strengths are applied and the sub-clouds are merged. Composite Chamfer Distance (CCD) is proposed as a distance between the input point cloud and the reconstruction composed of sub-clouds masked by activation strengths. We demonstrate that Skeleton Merger is capable of detecting semantically-rich salient keypoints with good alignment, and shows comparable performance to supervised methods on the KeypointNet dataset. It is also shown that the detector is robust to noise and subsampling.